Intro
I wanted to get back into ARM assembler so I wrote my own strlen. And then I looked at the strlen() glibc uses and did not understand a single thing. So I sat down and figured it out.
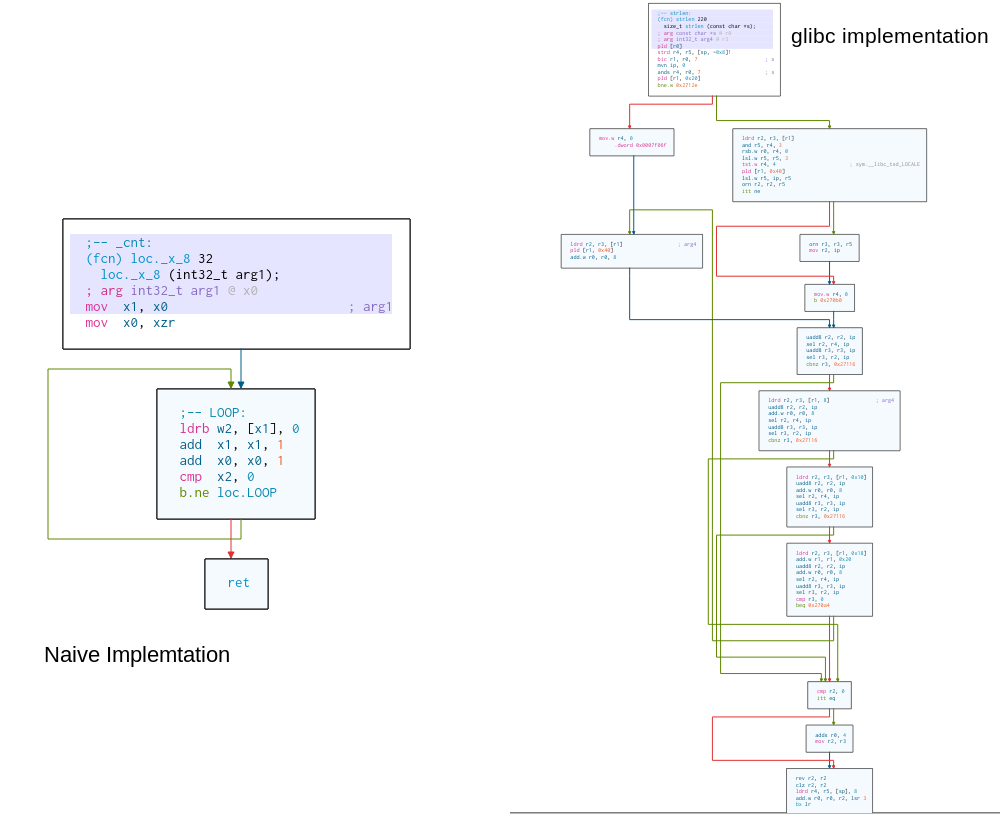
On the left you see a flow diagram of the building blocks of my naive implementation. On the right you see glibc’s. You might notice that it is more complex. (How much faster it is, and which optimization exactly makes it fast is an interesting topic. maybe another time)
I want to go through the function with a focus on two things:
- the actual counting (d’uh)
- the optimization if the string does not start on a word[0] boundary
1. The actual counting / the inner loop
The first thing I noticed about the inner loop is that it is unrolled. That is a fairly obvious optimization, made a bit harder because strlen does not clearly unroll as the input is cleanly divisible by word size. So on the end of every basic block there is a check which skips out of the loop and to the end where the result is calculated and returned.
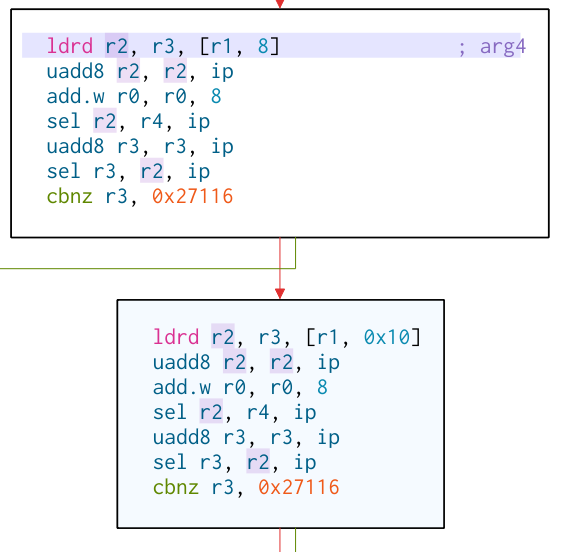
The basic blocks are basically identical. First the registers r2 and r3 are populated with the next two words to be checked for the null byte. Now r2 and r3 each contain one word (i.e. 4 bytes). How do you check whether there is a null byte somewhere in them? Without going through the bytes seperatly of course.
ARM processors have a status word called Application Program Status Register (APSR). It contains the result of ALU operations, for example if the operation overflowed, if it was zero, … It also has 4 bits corrosponding to the “Greater or Equal” (GE) result of the ARM SIMD[1] instructions. But every possible value is “greater or equal” to zero. So how does that help?
The bitwise opposite of 0 is 0xFF or 255 in decimal. Because it is the biggest possible value representable in one byte a GE comparion will only match if 0xFF is compared with 0xFF itself. The code already set up r12 to the value of 0xFFFFFFFF so one part of the equation is available. However the usual compare instructions do not set the 4 GE bits. They are only set by ADD16, ASX, SAX, SUB16, ADD8 and SUB8.
One possible way to turn a 0 into an 0xFF is to just add 0xFF. For all other values the result will overflow and be less. Luckily r12 already contains 4 bytes of 0xFF. And that is the second step in every basic block of the inner loop.
So for example if you had
r2 = 0x30313200, r12 = 0xffffff and ASPR.GE = [0, 0, 0, 0]
after r2 = r2 + r12 r2 contains 0x293031FF and ASPR.GE = [0, 0, 0, 1].
While it is great to know that where used to be a 0 now is a 0xFF it did not actually help. Instead of trying to figure out where a zero byte was now we have to figure out where a 0xFF is. So we did not actually gain anything.
The arm manual for the GE flags contains this little sentence:
These flags can control a later SEL instruction. For more information, see SEL on page A8-602.
The SEL opcode “selects each byte of its result from either its first operand or its second operand, according to the
values of the GE flags”. So this is a way to quickly eliminate all non zero (well non 0xFF) bytes.
SEL r2, r4, r12
r4 contains all zeros, so if the GE flag for this byte is false, the value from r4 is taken. r2 now contains a zero. Else it still contains the 0xFF.
Now you could just reverse that value and count the leading zeros to get the position of the null byte. However the ldrd
instruction did not only read one word into r2 but also one into r3. Since zero bytes are rare it would be a waste to not
also check if there maybe wasn’t one in the second word – which we already read anyway.
It also adds r12 to turn all zero bytes into 0xFF. However it can’t then do the exact same thing, because that would destroy the information from the previous word. So instead it SEL with r2 instead of an all zero register. That means that in the case that there was a null byte (and thus the GE flag is set) at this position in r3 the 0xFF from r12 is taken. If not however the value from r2 is. Which might or might not be a 0xFF.
If no zero byte was in those two words r3 will now be all zero. If not it will be something else. So the last instruction of
the basic block is a cbnz r3 skipping the next two unrolled blocks. This completes the inner loop.
2. Alignment
The ldrd instruction can not do unaligned accesses. But a string might be unaligned, for all sorts of reasons. (And POSIX probably mandates
that strlen() should handle unaligned strings). So like in all SIMD cases, there need to be a couple steps before the actual work begins. OFten
that is going through the data one byte at a time until it is aligned. However this implementation does something much smarter.
First it checks whether the string is unaligned by checking if the lower three bits are zero using straightforward bit twiddeling. But if they are not,
the code actually puts the argument into r1 and rounds down. So from now on it is safe to load from there. While doing that it puts by how much it rounded
down into r4 and then sets r0 to -r4. So effectively the result is that this string starts with a length of -4 instead of 0.
3. Other cute features
When calculating the end result, there is a problem. In every basic block (but the first one obv) the code already incremented the length. But now the null byte could be in either r2 or r3
– which is it? The code firstly checks if r2 is all zeros. If that is the case the it has to be r3. So there is a conditial move r2 = r3 and incrementing the length by 4.
(if you recall the length started counting at -4 also for unaligned access, so now the length would be zero)
It is reasonable to assume that every strlen() implementation will be memory bound. So at the beginning of the inner loop, there is a preload instruction to load the next cacheline. As there are 4 unrolled basic block, each checking 2 words the loop in total checks 64bits. which is exactly a cacheline. This ensure that the data to be checked should always be there, minimising waiting time.
4. Wrap up
Going through this was a valuable learning experience. I learned some new instructions, learned some new tricks (rev r2, r2 then clz r2, r2 to get the index in a word).
There are a couple obvious further topics just with this function:
is it even worth it? How much faster is this? Which trick contributed how much?
do those changes break anything? If it reads two words at a time, what happens if it reads into un-allocated memory?
how would it look with NEON instructions?
wait... i never even looked at a real life AMD64 implementation of strlen
it doesn't look like the code in glibc. What gives?
Footnotes [0] word as in machine width (32bit in this case), not the windows.h #define WORD. [1] Not NEON (Advanced SIMD).